
SpringCloud系列教程(三)之Open Feign
阅读提醒:
- 本文面向的是有一定springboot基础者
- 本次教程使用的Spring Cloud Hoxton RELEASE版本
- 本文依赖上一篇的工程,请查看上一篇文章以做到无缝衔接,或者直接下载源码:https://github.com/WinterChenS/spring-cloud-hoxton-study
前情概要
本文概览
- RPC是什么?
- Spring Cloud如何整合openfeign
- 如何使用ribbon和Hystrix 进行服务的负载均衡和服务熔断
- 实际的应用场景
上篇文章介绍了Spring Cloud如何整合Nacos作为配置中心和注册中心,接下来将介绍如何结合
Open Feign进行远程服务调用。在讲解OpenFeign之前我们需要了解一下RPC的基础概念。
本文中用到的demo源码地址:https://github.com/WinterChenS/spring-cloud-hoxton-study
什么是RPC?
在分布式计算,远程过程调用(英语:Remote Procedure Call,缩写为 RPC)是一个计算机通信协议。该协议允许运行于一台计算机的程序调用另一个地址空间(通常为一个开放网络的一台计算机)的子程序,而程序员就像调用本地程序一样,无需额外地为这个交互作用编程(无需关注细节)。RPC是一种服务器-客户端(Client/Server)模式,经典实现是一个通过发送请求-接受回应进行信息交互的系统。
如果涉及的软件采用面向对象编程,那么远程过程调用亦可称作远程调用或远程方法调用,例:Java RMI。
RPC是一种进程间通信的模式,程序分布在不同的地址空间里。如果在同一主机里,RPC可以通过不同的虚拟地址空间(即便使用相同的物理地址)进行通讯,而在不同的主机间,则通过不同的物理地址进行交互。许多技术(常常是不兼容)都是基于这种概念而实现的。
— 引用自维基百科
Feign与RPC的关系是什么?为什么有人觉得Feign是伪RPC?
其实Feign实现了可以通过像调用本地方法去调用远程服务的话,就是RPC,RPC最关键的两个协议是:
- 通讯协议
- 序列化协议
常用的rpc框架有:open feign 和 dubbo,feign基于http协议,dubbo基于tcp协议。
feign的原理:
feign集成了两个重要的模块:ribbon,Hystrix 来实现负载均衡和服务熔断,ribbon内置了RestTemplate, RestTemplate基于HTTP,所以说feign基于HTTP。
Feign通过处理注解,将请求模板化,当实际调用的时候,传入参数,根据参数再应用到请求上,进而转化成真正的 Request 请求。通过Feign以及JAVA的动态代理机制,使得Java 开发人员,可以不用通过HTTP框架去封装HTTP请求报文的方式,完成远程服务的HTTP调用。
Spring Cloud集成feign
根据上篇的文章中我们使用的Nacos作为代码基础,在此之上集成Feign,所以请查看上一篇文章以做到无缝衔接。
spring-cloud-nacos-provider 修改:
在工程spring-cloud-nacos-provider 中增加依赖:
1 | |
新建一个类:NacosProviderClient 并增加注解:@FeignClient(value = "winter-nacos-provider")
1 | |
类:NacosController 增加方法:
1 | |
spring-cloud-nacos-consumer 修改:
在工程spring-cloud-nacos-consumer 中增加依赖:
1 | |
在启动类NacosConsumerApplication 中增加注解:@EnableFeignClients
1 | |
在类:NacosController 中增加方法:
1 | |
测试:
- 依次启动两个服务;
- 浏览器输入:http://127.0.0.1:16011/nacos/feign-test/hello
- 返回:Hello feign hello 就表示成功了
使用Ribbon
Feign内置了ribbon用于服务的负载均衡,所以只需要引入feign的依赖就会自动使用负载均衡,接下来我们试一下服务的负载均衡:
spring-cloud-nacos-provider 修改:
NacosController 新增方法和参数:
1 | |
NacosProviderClient 新增接口:
1 | |
为了测试服务的负载,所以provider服务不使用配置中心的配置,删除配置中心的配置,然后新建application.yml 配置文件,内容如下:
1 | |
spring-cloud-nacos-consumer 修改
NacosController 新增方法:
1 | |
测试:
在测试之前需要修改idea的配置,红色方框处勾选之后服务可以启动多个节点

依次启动两个服务,然后修改spring-cloud-nacos-provider 的端口配置
1 | |
然后再次启动spring-cloud-nacos-provider 服务,启动后该服务存在两个节点
然后调用:http://127.0.0.1:16011/nacos/ribbon-test
可以发现请求会轮流调用:
1 | |
这样就实现了服务的负载均衡。
Ribbon的配置
可以配置Ribbon的一些参数实现更多的控制,简单的介绍一下Ribbon的配置,我们可以在consumer工程的配置文件中增加:
1 | |
1 | |
Hystrix 使用
除了上面提到的Ribbon,Feign还集成了Hystrix 作为服务熔断组件,服务为什么需要熔断呢?是因为一旦下层服务超时或异常导致不可用,没有熔断机制会导致整个服务集群宕机,所以在微服务架构中,服务的熔断是非常重要的。
spring-cloud-nacos-provider 修改:
NacosController 新增方法:
1 | |
新增类NacosProviderClientFallback 并实现接口NacosProviderClient :
1 | |
修改NacosProviderClient ,新增方法并且@FeignClient 注解增加fallback 参数,该参数就是服务降级的类,当服务不可用会调用此类的实现方法。
1 | |
spring-cloud-nacos-consumer 修改
增加配置:
1 | |
注释的注解都是新增的,如果要特定某个服务的配置,就不写default,直接指定服务名就可以,如上面的配置。
测试
分别启动两个服务,然后调用:http://127.0.0.1:16011/nacos/hystrix-test
返回的响应:hystrix error
拓展:hystrix的配置
线程池配置
| Name | 备注 | 默认值 |
|——————————————————————|—————————————————|——-|
| hystrix.threadpool.default.coreSize | 线程池大小 | 10 |
| hystrix.threadpool.default.maximumSize | 线程池最大大小 | 10 |
| hystrix.threadpool.default.allowMaximumSizeToDivergeFromCoreSize | 是否允许动态调整线程数量,默认false,只有设置为true了,上面的maximumSize才有效 | FALSE |
| hystrix.threadpool.default.keepAliveTimeMinutes | 超出coreSize的线程,空闲1分钟后释放掉 | 1 |
| hystrix.threadpool.default.maxQueueSize | 不能动态修改 | -1 |
| hystrix.threadpool.default.queueSizeRejectionThreshold | 可以动态修改,默认是5,先进入请求队列,然后再由线程池执行 | 5 |
如何计算线程池数量?
高峰期每秒的请求数量 / 1000毫秒 / TP99请求延时 + buffer空间
比如说处理一个请求,要50ms,那么TP99,也就是99%的请求里处理一个请求耗时最长是50ms。
我们给一点缓冲空间10ms,那就是处理请求接口耗时60ms。
所以一秒钟一个线程可以处理:1000 / 60 = 16,一个线程一秒钟可以处理16个请求。
假设高峰期,每秒最多1200个请求,一个线程每秒可以处理16个请求,需要多少个线程才能处理每秒1200个请求呢?1200 / 16 = 75,最多需要75个线程,每个线程每秒处理16个请求,75个线程每秒才可以处理1200个请求。
最多需要多少个线程数量,就是这样子算出来
如果是服务B -> 服务A的话,服务B线程数量怎么设置?
服务B调用服务A的线程池需要多少个线程呢?
高峰期,服务B最多要调用服务A每秒钟1200次,服务A处理一个请求是60ms,服务B每次调用服务A的时候,用一个线程发起一次请求,那么这个服务B的这个线程,要60ms才能返回。
服务B而言,一个线程对服务A发起一次请求需要60ms,一个线程每秒钟可以请求服务A达到16次,但是现在服务B每秒钟需要请求服务A达到1200次,那么服务B就需要75个线程,在高峰期并发请求服务A,才可以完成每秒1200次的调用。
服务B,部署多台机器,每台机器调用服务A的线程池有10个线程,比如说搞个10个线程,一共部署10台机器,那么服务B调用服务A的线程数量,一共有100个线程,轻轻松松可以支撑高峰期调用服务A的1200次的场景
每个线程调用服务A一次,耗时60ms,每个线程每秒可以调用服务A一共是16次,100个线程,每秒最多可以调用服务A是1600次,高峰的时候只要支持调用服务A的1200次就可以了,所以这个机器部署就绰绰有余了
执行配置
| Name | 备注 | 默认值 |
|—————————————————————————–|——————————–|——–|
| hystrix.command.default.execution.isolation.strategy | 隔离策略,默认Thread,可以选择Semaphore信号量 | Thread |
| hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds | 超时时间 | 1000ms |
| hystrix.command.default.execution.timeout.enabled | 是否启用超时 | TRUE |
| hystrix.command.default.execution.isolation.thread.interruptOnTimeout | 超时的时候是否中断执行 | TRUE |
| hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests | 信号量隔离策略下,允许的最大并发请求数量 | 10 |
降级配置
| Name | 备注 | 默认值 |
|——————————————|——–|——|
| hystrix.command.default.fallback.enabled | 是否启用降级 | TRUE |
熔断配置
| Name | 备注 | 默认值 |
|——————————————————————|————————————————-|——|
| hystrix.command.default.circuitBreaker.enabled | 是否启用熔断器 | TRUE |
| hystrix.command.default.circuitBreaker.requestVolumeThreshold | 10秒钟内,请求数量达到多少才能去尝试触发熔断 | 20 |
| hystrix.command.default.circuitBreaker.errorThresholdPercentage | 10秒钟内,请求数量达到20,同时异常比例达到50%,就会触发熔断 | 50 |
| hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds | 触发熔断之后,5s内直接拒绝请求,走降级逻辑,5s后尝试half-open放过少量流量试着恢复 | 5000 |
| hystrix.command.default.circuitBreaker.forceOpen | 强制打开熔断器 | |
| hystrix.command.default.circuitBreaker.forceClosed | 强制关闭熔断器 | |
监控配置
| Name | 备注 | 默认值 |
|———————————————————————–|———————————————————————————————————————————————————–|—————|
| hystrix.threadpool.default.metrics.rollingStats.timeInMillisecond | 线程池统计指标的时间 | 默认10000,就是10s |
| hystrix.threadpool.default.metrics.rollingStats.numBuckets | 将rolling window划分为n个buckets | 10 |
| hystrix.command.default.metrics.rollingStats.timeInMilliseconds | command的统计时间,熔断器是否打开会根据1个rolling window的统计来计算。若rolling window被设为10000毫秒,则rolling window会被分成n个buckets,每个bucket包含success,failure,timeout,rejection的次数的统计信息。 | 10000 |
| hystrix.command.default.metrics.rollingStats.numBuckets | 设置一个rolling window被划分的数量,若numBuckets=10,rolling window=10000,那么一个bucket的时间即1秒。必须符合rolling window % numberBuckets == 0 | 10 |
| hystrix.command.default.metrics.rollingPercentile.enabled | 执行时是否enable指标的计算和跟踪 | TRUE |
| hystrix.command.default.metrics.rollingPercentile.timeInMilliseconds | 设置rolling percentile window的时间 | 60000 |
| hystrix.command.default.metrics.rollingPercentile.numBuckets | 设置rolling percentile window的numberBuckets。逻辑同上。 | 6 |
| hystrix.command.default.metrics.rollingPercentile.bucketSize | 如果bucket size=100,window=10s,若这10s里有500次执行,只有最后100次执行会被统计到bucket里去。增加该值会增加内存开销以及排序的开销。 | 100 |
| hystrix.command.default.metrics.healthSnapshot.intervalInMilliseconds | 记录health 快照(用来统计成功和错误绿)的间隔 | 500ms |
高阶特性配置
| Name | 备注 | 默认值 |
|—————————————————-|——————————————————————|——————-|
| hystrix.command.default.requestCache.enabled | 是否启用请求缓存 | TRUE |
| hystrix.command.default.requestLog.enabled | 记录日志到HystrixRequestLog | TRUE |
| hystrix.collapser.default.maxRequestsInBatch | 单次批处理的最大请求数,达到该数量触发批处理 | Integer.MAX_VALUE |
| hystrix.collapser.default.timerDelayInMilliseconds | 触发批处理的延迟,也可以为创建批处理的时间+该值 | 10 |
| hystrix.collapser.default.requestCache.enabled | 是否对HystrixCollapser.execute() and HystrixCollapser.queue()的cache | TRUE |
Feign和Hystrix结合的原理
Feign在和Hystrix整合的时候,feign动态代理里面有一些Hystrix相关的代码,请求走feign动态代理的时候,就会基于Hystrix Command发送请求,实现服务间调用的隔离、限流、超时、降级、熔断、统计等。
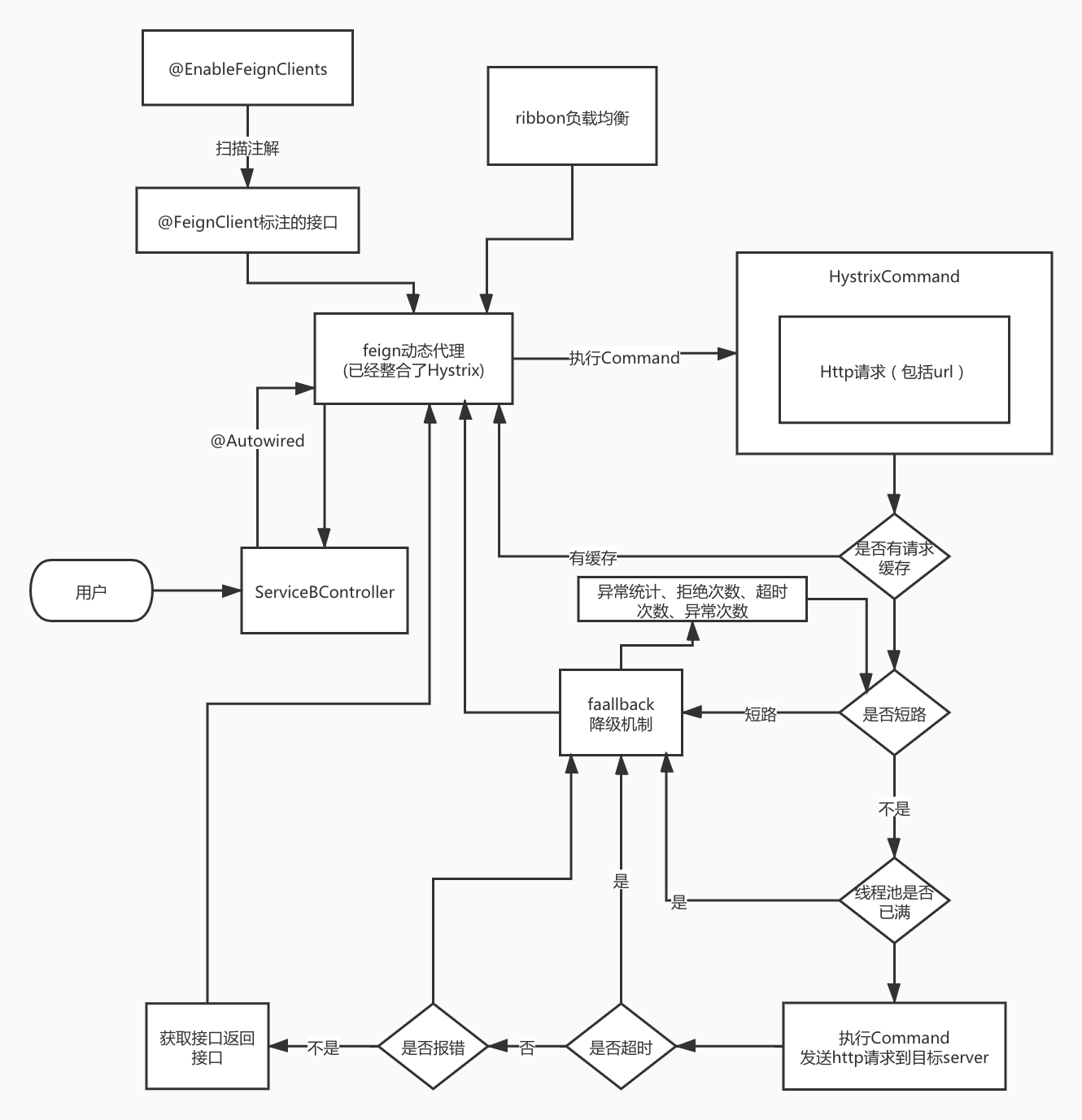 http://www.saily.top/img/spring-cloud/Feign%E5%92%8CHystrix%E7%9A%84%E6%A0%B8%E5%BF%83%E5%8E%9F%E7%90%86.jpg
http://www.saily.top/img/spring-cloud/Feign%E5%92%8CHystrix%E7%9A%84%E6%A0%B8%E5%BF%83%E5%8E%9F%E7%90%86.jpg
总结
本文学习了springcloud整合feign实现远程服务调用,并且使用了feign集成的Ribbon和Hystrix实现的负载均衡和服务熔断,以及对服务负载均衡和熔断进行了深度的了解和实际使用当中的一些配置,下一篇将会讲讲微服务网关SpringCloud Gateway。
源码地址
https://github.com/WinterChenS/spring-cloud-hoxton-study
参考文档:
- 本文作者:winter chen
- 本文链接:https://blog.winterchen.com/2021/08/02/2021-08-02-spring-cloud-hoxton-3-feign/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!